Wi-Fi Fingerprint Indoor Localization (Part III): Classification and Cascade Prediction
7 minute read
In the previous post, we performed various transformations on the independent variables of the raw UJIIndoorLoc dataset to prepare it for the machine learning.
In this notebook, we first perform the building and floor classification. Then, we study the indoor positioning accuracy.
1. Building and Floor Classification
In this sub-section, I quickly evaluate the performance of various models for building classification, floor classification and per-building floor classification. My project partner Kumail found Random Forests with 100 trees to provide the best performance and I will primarily focus on it’s performance.
Before I begin the evaluation, let’s write a few functions that will come handy.
def multiclass_roc(estimator, X_train,y_train,X_test,y_test,
classes_list,
decision = 'predict_proba',
title = None):
# Binarize the output
y_train = label_binarize(y_train, classes=classes_list)
n_classes = y_train.shape[1]
y_test = label_binarize(y_test, classes=classes_list)
# Learn to predict each class against the other
classifier = OneVsRestClassifier(estimator)
classifier.fit(X_train, y_train)
if decision == 'decision_function':
y_score = classifier.decision_function(X_test)
elif decision == 'predict_proba':
y_score = classifier.predict_proba(X_test)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
# Compute macro-average ROC curve and ROC area
# First aggregate all false positive rates
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
# Finally average it and compute AUC
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
# Plot all ROC curves
plt.figure(figsize=(10,8))
plt.plot(fpr["micro"], tpr["micro"],
label='micro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["micro"]),
color='deeppink', linestyle=':', linewidth=4)
plt.plot(fpr["macro"], tpr["macro"],
label='macro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
colors = cycle(['aqua', 'darkorange', 'cornflowerblue'])
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
if title:
plt.title(title)
plt.legend(loc="lower right")
plt.tight_layout()
plt.show()
y_building_train = y_crossval['BUILDINGID']
y_building_test = y_holdout['BUILDINGID']
y_building_train.shape,y_building_test.shape
((17874,), (1987,))
RANDOM_STATE = np.random.RandomState(0)
sm = SMOTE(random_state=RANDOM_STATE)
nm = NearMiss(version=2, random_state=RANDOM_STATE)
rf = RandomForestClassifier(n_estimators=100, random_state=RANDOM_STATE)
pipe_rf = make_pipeline(nm,rf)
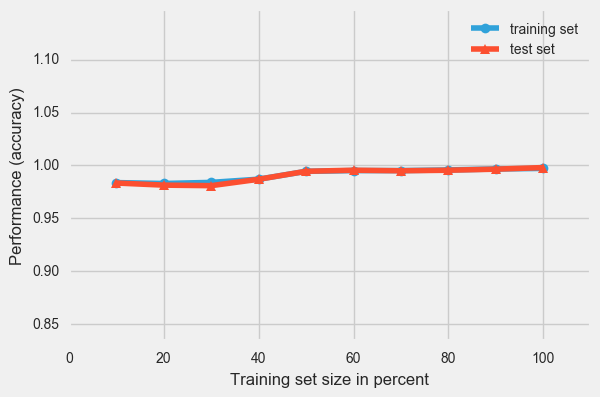
plot_learning_curves(X_train, y_building_train,
X_test, y_building_test,
pipe_rf, scoring = 'accuracy',
print_model = False)
plt.show()
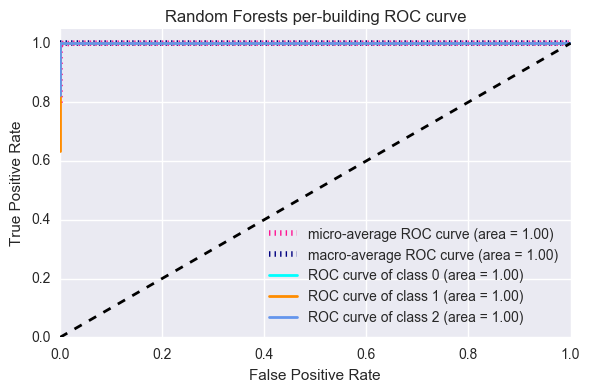
multiclass_roc(pipe_rf, X_train,y_building_train,X_test,y_building_test,
[0,1,2],
decision = 'predict_proba',
title = 'Random Forests per-building ROC curve')
2. Floor Classification
y_floor_train = y_crossval['FLOOR']
y_floor_test = y_holdout['FLOOR']
RANDOM_STATE = np.random.RandomState(0)
sm = SMOTE(random_state=RANDOM_STATE)
nm = NearMiss(version=2, random_state=RANDOM_STATE)
rf = RandomForestClassifier(n_estimators=100, random_state=RANDOM_STATE)
pipe_rf_floor = make_pipeline(nm,rf)
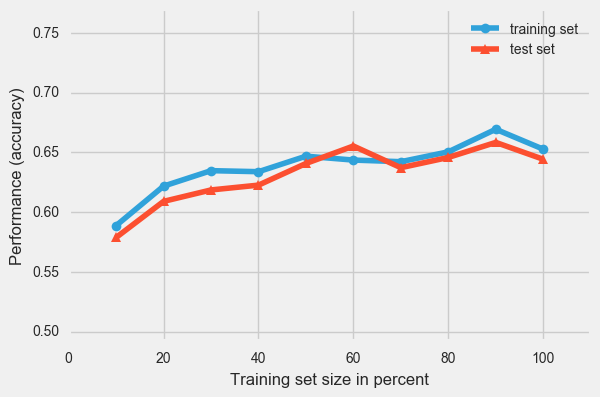
plot_learning_curves(X_train, y_floor_train,
X_test, y_floor_test,
pipe_rf, scoring = 'accuracy',
print_model = False)
([0.58869613878007832,
0.62171236709569111,
0.63465124953375607,
0.63379493635473494,
0.64674946850173431,
0.64350988437150314,
0.64215490368475736,
0.65039513252675007,
0.6692776327241079,
0.65262392301667227],
[0.5787619526925013,
0.60895822848515346,
0.61852038248616004,
0.62254655259184699,
0.6406643180674384,
0.65525918470055355,
0.63714141922496226,
0.64569703069954709,
0.65827881227981877,
0.64418721690991443])
multiclass_roc(pipe_rf, X_train,y_floor_train,X_test,y_floor_test,
[0,1,2,3,4],
decision = 'predict_proba',
title = 'Random Forests per-Floor ROC curve')
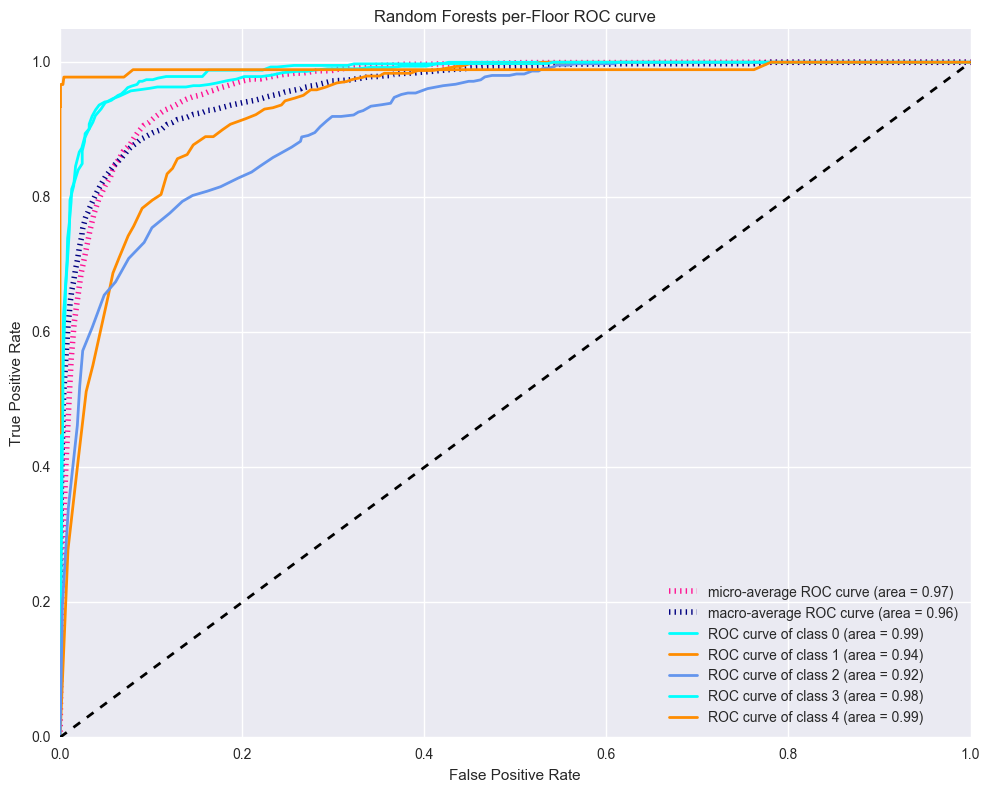
2.1 Per-Building Floor Classification
# b indicates building
X_crossval_b = {}
y_crossval_b = {}
X_holdout_b = {}
y_holdout_b = {}
for building in buildings:
# Finding index of samples with the building and floor
index_crossval_b = y_crossval[y_crossval.BUILDINGID == building].index
index_holdout_b = y_holdout[y_holdout.BUILDINGID == building].index
if len(index_crossval_b) == 0:
continue
key = (building)
X_crossval_b[key] = X_pca_crossval.loc[index_crossval_b]
y_crossval_b[key] = y_crossval.loc[index_crossval_b,'FLOOR']
X_holdout_b[key] = X_pca_holdout.loc[index_holdout_b]
y_holdout_b[key] = y_holdout.loc[index_holdout_b,'FLOOR']
print("Building = {}".format(building))
print("Crossval shape", len(index_crossval_b))
print("Holdout shape", len(index_holdout_b))
#X_crossval_b.keys(), X_holdout_b.keys(),
Building = 2
Crossval shape 8511
Holdout shape 943
Building = 0
Crossval shape 4704
Holdout shape 544
Building = 1
Crossval shape 4659
Holdout shape 500
clf_knn = Pipeline([('scl', StandardScaler()),
('reg', KNeighborsClassifier(n_neighbors=3,
metric='manhattan',
weights = 'distance'))])
# Random Forests
clf_rf = RandomForestClassifier(random_state=1, n_estimators=50)
# Extra Trees
clf_et = ExtraTreesClassifier(random_state=1,n_estimators=50)
clfs = [clf_knn,clf_rf,clf_et]
clf_labels = ['KNN','Random Forests','Extra Trees']
clf_dict = dict(zip(clf_labels, clfs))
best_local_crossval_b = {}
best_local_train_b = {}
best_local_holdout_b = {}
best_local_model = {}
for key in X_crossval_b:
print("Building = {}".format(key))
X_train_b = X_crossval_b[key]
y_train_b = y_crossval_b[key]
X_test_b = X_holdout_b[key]
y_test_b = y_holdout_b[key]
max_accu= 0
for clf_label in clf_dict:
model = clf_dict[clf_label]
crossval_score = np.sqrt(np.abs((cross_val_score(estimator=model,
X=X_train_b,
y=y_train_b,
cv=10,
n_jobs=1,
scoring = 'accuracy'))))
if np.mean(crossval_score) > max_accu:
best_local_model[key] = clf_label
best_local_crossval_b[key] = crossval_score
print('CV accuracy: %.3f +/- %.3f' % (np.mean(best_local_crossval_b[key]),
np.std(best_local_crossval_b[key])))
# Best RMSE
best_model = clf_dict[best_local_model[key]]
best_model.fit(X_train_b,y_train_b)
y_predict_train = best_model.predict(X_train_b)
best_local_train_b[key] = accuracy_score(y_train_b, y_predict_train)
print('Local Training Accuracy: %.3f' % (best_local_train_b[key]))
y_predict_holdout = best_model.predict(X_test_b)
best_local_holdout_b[key] = accuracy_score(y_test_b, y_predict_holdout)
print('Local Holdout RMSE: %.3f' % (best_local_holdout_b[key]))
Building = 0
CV accuracy: 0.978 +/- 0.002
Local Training Accuracy: 1.000
Local Holdout RMSE: 0.943
Building = 1
CV accuracy: 0.986 +/- 0.004
Local Training Accuracy: 1.000
Local Holdout RMSE: 0.956
Building = 2
CV accuracy: 0.989 +/- 0.002
Local Training Accuracy: 1.000
Local Holdout RMSE: 0.975
best_local_crossval_b = pd.Series(best_local_crossval_b)
best_local_floor_clf = (pd.concat([pd.Series(best_local_model),
best_local_crossval_b.apply(np.mean),
best_local_crossval_b.apply(np.std),
pd.Series(best_local_train_b),
pd.Series(best_local_holdout_b)],
axis=1))
best_local_floor_clf.columns = ['BEST_LOCAL_MODEL','BEST_LOCAL_CROSSVAL_MEAN','BEST_LOCAL_CROSSVAL_STD',
'BEST_LOCAL_TRAINING_ACCURACY','BEST_LOCAL_HOLDOUT_ACCURACY']
best_local_floor_clf = best_local_floor_clf.rename_axis(['BUILDING'])
best_local_floor_clf
| BEST_LOCAL_MODEL | BEST_LOCAL_CROSSVAL_MEAN | BEST_LOCAL_CROSSVAL_STD | BEST_LOCAL_TRAINING_ACCURACY | BEST_LOCAL_HOLDOUT_ACCURACY | |
|---|---|---|---|---|---|
| BUILDING | |||||
| 0 | KNN | 0.978295 | 0.002010 | 1.0 | 0.943015 |
| 1 | KNN | 0.986483 | 0.004177 | 1.0 | 0.956000 |
| 2 | KNN | 0.989367 | 0.002324 | 1.0 | 0.974549 |
We observe the per-building Floor Classification greatly improves the accuracy!
# First, let's save our data into a file
f = open("best_local_floor_clf.pckl", "wb")
pickle.dump(best_local_floor_clf,f)
3. The Final Problem
In this final sub-section, I perform the complete cascade modeling and evaluation of our indoor positioning problem. For that purpose, first our models need to be trained combining the training and holdout set.
Building Classification
Per-Building Floor Classification
Per-Building and Per-Floor Regression
X_train = pd.concat([X_pca_crossval,X_pca_holdout],axis=0)
y_train = pd.concat([y_crossval,y_holdout],axis=0)
## Final test data
X_test = pd.read_csv("data/X_pca_test.csv",index_col=0)
y_test = pd.read_csv("data/y_test.csv",index_col=0)
record_train = pd.concat([X_train,y_train],axis=1)
record_test = pd.concat([X_test,y_test],axis=1)
3.1 Model Fitting
# Building Fitting
RANDOM_STATE = np.random.RandomState(0)
sm = SMOTE(random_state=RANDOM_STATE)
nm = NearMiss(version=2, random_state=RANDOM_STATE)
rf = RandomForestClassifier(n_estimators=100, random_state=RANDOM_STATE)
# Building
building_clf = make_pipeline(nm,rf)
building_clf.fit(X_train, y_train['BUILDINGID'])
Pipeline(steps=[('nearmiss', NearMiss(n_jobs=1, n_neighbors=3, n_neighbors_ver3=3,
random_state=<mtrand.RandomState object at 0x10ff9fee8>, ratio='auto',
return_indices=False, size_ngh=None, ver3_samp_ngh=None, version=2)), ('randomforestclassifier', RandomForestClassifier(bootstrap=True, class_wei... random_state=<mtrand.RandomState object at 0x10ff9fee8>,
verbose=0, warm_start=False))])
# Per-Building Floor Fitting
floor_clf_models = {}
for building in buildings:
#model = clf_dict[model]
model = clf_dict[best_local_floor_clf.loc[building]['BEST_LOCAL_MODEL']]
print(model)
X_train_b = pd.concat([X_crossval_b[building],X_holdout_b[building]],axis=0)
y_train_b = pd.concat([y_crossval_b[building],y_holdout_b[building]],axis=0)
model.fit(X_train_b,y_train_b)
floor_clf_models[building] = model
Pipeline(steps=[('scl', StandardScaler(copy=True, with_mean=True, with_std=True)), ('reg', KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='manhattan',
metric_params=None, n_jobs=1, n_neighbors=3, p=2,
weights='distance'))])
Pipeline(steps=[('scl', StandardScaler(copy=True, with_mean=True, with_std=True)), ('reg', KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='manhattan',
metric_params=None, n_jobs=1, n_neighbors=3, p=2,
weights='distance'))])
Pipeline(steps=[('scl', StandardScaler(copy=True, with_mean=True, with_std=True)), ('reg', KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='manhattan',
metric_params=None, n_jobs=1, n_neighbors=3, p=2,
weights='distance'))])
# Per-Building Per-Floor Regression Fitting
regression_models = {}
for key in X_crossval_bf:
model = reg_dict[best_local_metric_df.loc[key[0],key[1]]['BEST_LOCAL_MODEL']]
X_train_bf = pd.concat([X_crossval_bf[key],X_holdout_bf[key]],axis=0)
y_train_bf = pd.concat([y_crossval_bf[key],y_holdout_bf[key]],axis=0)
model.fit(X_train_bf,y_train_bf)
regression_models[key] = model
3.2 Localization Prediction
For each sample in the training and test data, we compute the error metric given by
$positioning_error(actual,predicted)= euclidean_distance(actual,predicted) + penalty_{floor}fail_{floor} + penalty_{building}fail_{building}$
gs_knn_best.fit(X_train,y_train[['LATITUDE','LONGITUDE']])
Pipeline(steps=[('scl', StandardScaler(copy=True, with_mean=True, with_std=True)), ('reg', KNeighborsRegressor(algorithm='auto', leaf_size=30, metric='manhattan',
metric_params=None, n_jobs=-1, n_neighbors=3, p=2,
weights='distance'))])
def compute_final_error(record):
penalty_building = 50
penalty_floor = 4
X = record.iloc[:150]
y = record.iloc[150:]
# Building classification
building_pred = building_clf.predict(X)[0]
#print(building_pred)
# Floor Classification
floor_pred = floor_clf_models[building].predict(X)[0]
#print(floor_pred)
# Latitude and Longitude Prediction
#lat_long_pred = regression_models[(building_pred,floor_pred)].predict(X)
lat_long_pred = gs_knn_best.predict(X)
lat_pred = lat_long_pred[0][0]
long_pred = lat_long_pred[0][1]
penalty = 0
# Building Penalty
if building_pred != y['BUILDINGID']:
penalty += penalty_building
#print("After building: ", penalty)
# Floor Penalty
if floor_pred != y['FLOOR']:
penalty += penalty_floor
#print("After floor: ", penalty)
# Latitude-Longitude Penalty
lat_actual, long_actual = y['LATITUDE'], y['LONGITUDE']
#penalty += np.sqrt(((lat_long_pred - y[['LATITUDE','LONGITUDE']])**2).sum(axis=1))
penalty += np.sqrt((long_pred - long_actual) ** 2 + (lat_pred - lat_actual) ** 2)
return penalty
record_train['ERROR'] = record_train.apply(compute_final_error,axis = 1)
record_test['ERROR'] = record_test.apply(compute_final_error,axis = 1)
eval_train = record_train.iloc[:,152:]
eval_test = record_test.iloc[:,152:]
eval_train.head()
| FLOOR | BUILDINGID | SPACEID | RELATIVEPOSITION | ERROR | |
|---|---|---|---|---|---|
| 14651 | 1 | 2 | 117 | 2 | 4.0 |
| 16771 | 3 | 0 | 108 | 2 | 0.0 |
| 17601 | 3 | 0 | 107 | 2 | 0.0 |
| 6651 | 0 | 2 | 103 | 2 | 4.0 |
| 86 | 3 | 2 | 222 | 2 | 0.0 |
(sns.factorplot(x="FLOOR",y="ERROR",hue="BUILDINGID",
kind="violin",data=eval_train,
size = 10,
aspect = 1.0,
legend_out = False))
plt.ylim([-3,15])
plt.xlim([-1,6])
plt.legend(loc='lower right', fontsize=20, title='BUILDING ID')
<matplotlib.legend.Legend at 0x1351cc5f8>
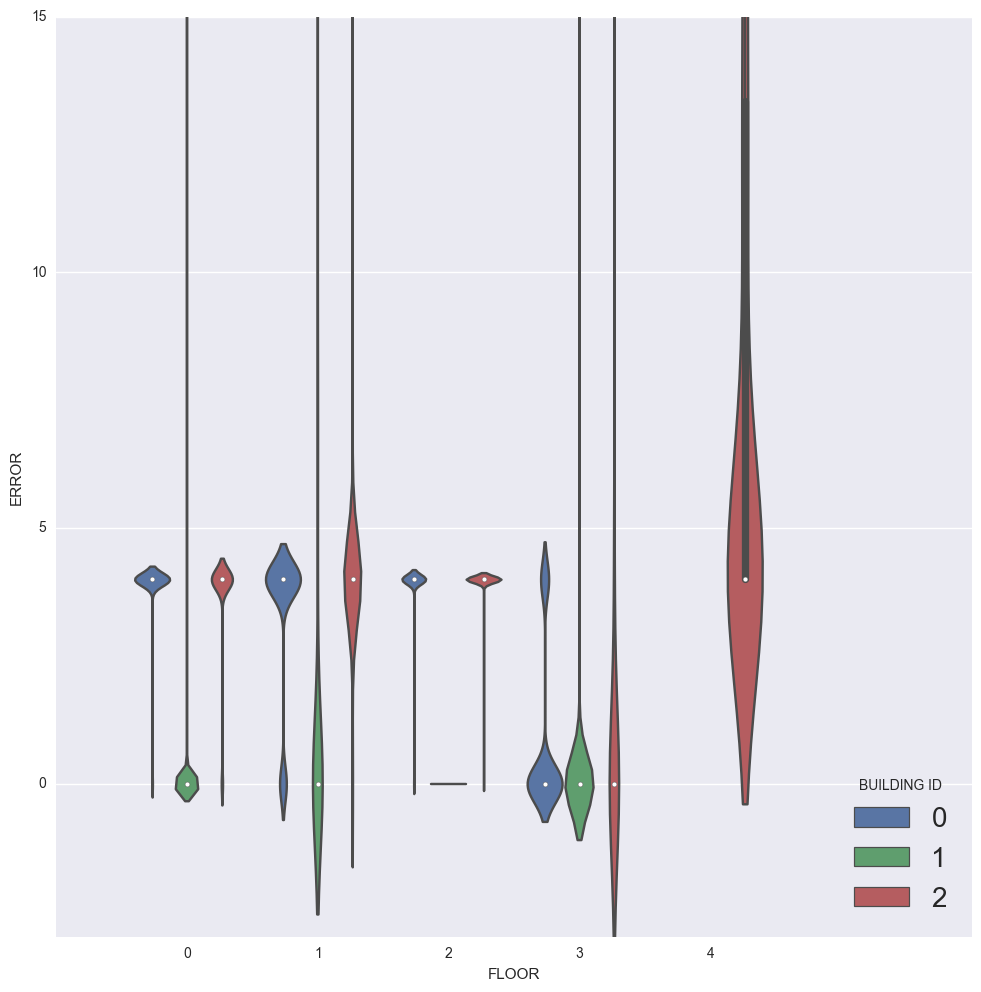
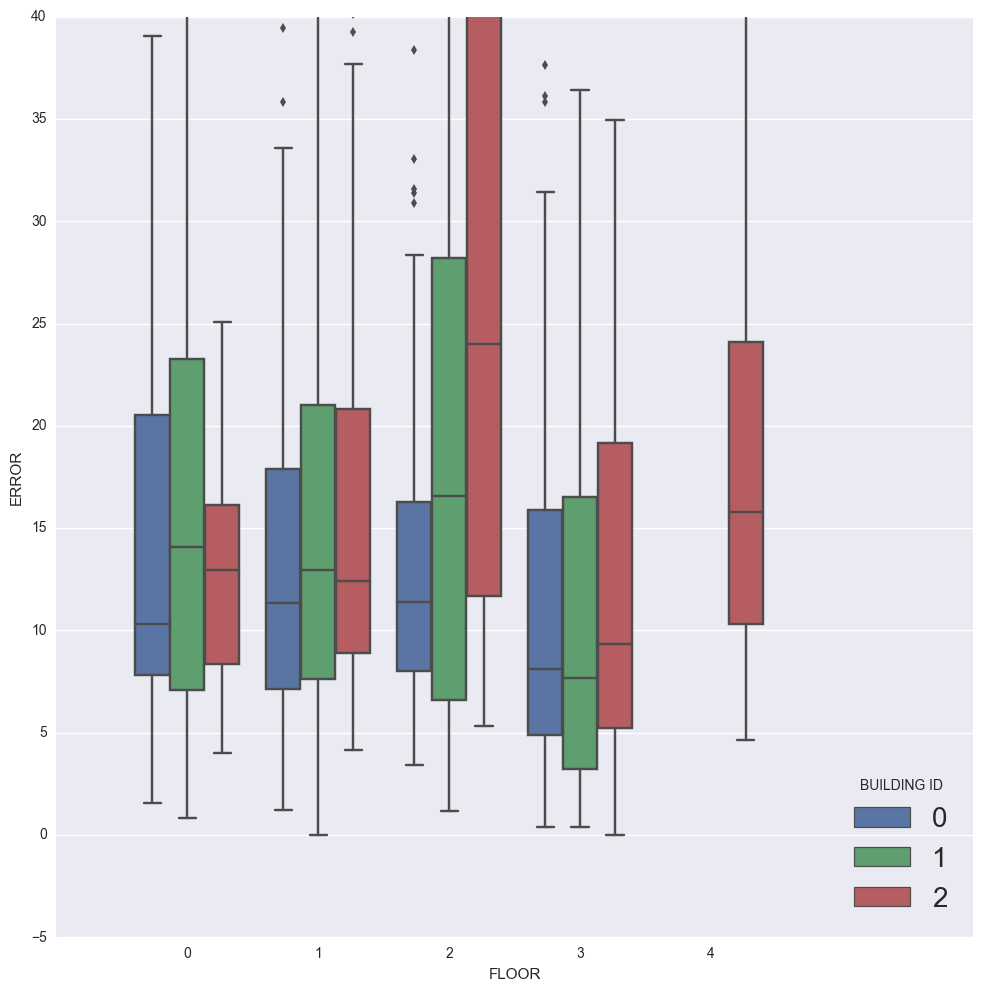
(sns.factorplot(x="FLOOR",y="ERROR",hue="BUILDINGID",
kind="box",data=eval_test,
size = 10,
aspect = 1.0,
legend_out = False))
plt.ylim([-5,40])
plt.xlim([-1,6])
plt.legend(loc='lower right', fontsize=20, title='BUILDING ID')
<matplotlib.legend.Legend at 0x136f87320>