
Wi-Fi Fingerprint Indoor Localization (Part I): Predictor Pre-Processing
17 minute read
This post is part of a series of blogs on machine learning approaches for Wi-Fi fingerprinting based indoor localization.
In this series, I begin from the raw UJIIndoorLoc dataset and perform an initial exploratory data analysis on the distributions of the predictors. This is followed by dimensionality reduction analysis. Once the data is prepared, I focus on understanding the response characteristics and cost function formulation. Once the response is well-understood, I utilize cross-validation to evaluate various machine learning models. Finally, the best models are chosen to form a superior ensemble for indoor fingerprinting-based localization.
The code used in this blog can be found on GitHub.
1. Indoor Localization
Automatic user localization consists of estimating the position of the user (latitude, longitude and altitude) by using an electronic device, usually a mobile phone. Outdoor localization problem can be solved very accurately thanks to the inclusion of GPS sensors into the mobile devices. However, indoor localization is still an open problem mainly due to the loss of GPS signal in indoor environments. With the widespread use of Wi-Fi communication in indoor environments, Wi-Fi or wireless local area network (WLAN) based positioning gained popularity to solve indoor localization.
WLAN-based positioning systems utilize the Wi-Fi received signal strength indicator (RSSI) value. In this project, we focus on fingerprint-based localization. Fingerprinting technique consists of two phases: calibration and positioning. In the calibration phase, an extensive radio map is built consisting of RSSI values from multiple Wi-Fi Access Points (APs) at different known locations. This calibration data is used to train the localization algorithm. In the positioning phase, when a user reports the RSSI measurements for the multiple APs, the algorithm that is fit predicts the user position.
A key challenge in wireless localization is that RSSI value at a given location can have large fluctuations due to Wi-Fi interference, user mobility, environmental mobility etc.
Let’s begin the analysis!
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels
import matplotlib.pyplot as plt
import matplotlib
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
import seaborn as sns
train_data = pd.read_csv("data/trainingData.csv")
test_data = pd.read_csv("data/validationData.csv")
2. Dataset Description
UjiIndoorLoc is the first publicly-available database for indoor localization. With the help of this database, researchers can now compare and benchmark state-of-the-art algorithms. Part of the motivation was the famous MNIST dataset which is a standard dataset used in the field of Computer Vision for performance evaluation.
Source: https://www.kaggle.com/giantuji/UjiIndoorLoc
WAP001-WAP520: Intensity value for Wireless Access Point (WAP). WAP will be the acronym used for rest of this notebook. Negative integer values from -104 to 0 and +100. Censored data: Positive value 100 used if WAP was not detected.
Longitude: Longitude. Negative real values from -7695.9387549299299000 to -7299.786516730871000
Latitude: Latitude. Positive real values from 4864745.7450159714 to 4865017.3646842018.
Floor: Altitude in floors inside the building. Integer values from 0 to 4.
BuildingID: ID to identify the building. Measures were taken in three different buildings. Categorical integer values from 0 to 2.
SpaceID: Internal ID number to identify the Space (office, corridor, classroom) where the capture was taken. Categorical integer values.
RelativePosition: Relative position with respect to the Space (1 - Inside, 2 - Outside in Front of the door). Categorical integer values.
UserID: User identifier (see below). Categorical integer values.
PhoneID: Android device identifier (see below). Categorical integer values.
Timestamp: UNIX Time when the capture was taken. Integer value.
# Response variables in our problem are Building, Floor, Latitude, Longitude and Relative Position
(train_data[['FLOOR','BUILDINGID', 'SPACEID','RELATIVEPOSITION','USERID','PHONEID']]
.astype(str)
.describe(include=['object']))
| FLOOR | BUILDINGID | SPACEID | RELATIVEPOSITION | USERID | PHONEID | |
|---|---|---|---|---|---|---|
| count | 19937 | 19937 | 19937 | 19937 | 19937 | 19937 |
| unique | 5 | 3 | 123 | 2 | 18 | 16 |
| top | 3 | 2 | 202 | 2 | 11 | 14 |
| freq | 5048 | 9492 | 484 | 16608 | 4516 | 4835 |
From the paper on this dataset: “Although both the training subset and the validation subset contain the same information, the latter includes the value 0 in some fields. These fields are: SpaceID, Relative Position with respect to SpaceID and UserID. As it has been commented before, this information was not recorded because the validation captures were taken at arbitrary points and the users were not tracked in this phase. This fact tries to simulate a real localization system.”
Hence, Space ID, Relative Position, User ID won’t be used to model the Localization algorithm. Also, Phone iD won’t be used as in a real system, new phones should be localized without being used in the training.
Next, I focus on the pre-processing of the WAP RSSI columns.
3. Exploratory Data Analysis
X_train = train_data.iloc[:,:520]
X_test = test_data.iloc[:,:520]
y_train = train_data.iloc[:,520:526]
y_test = test_data.iloc[:,520:526]
X_train = (X_train
.replace(to_replace=100,value=np.nan))
# Perform the same transform on Test data
X_test = (X_test
.replace(to_replace=100,value=np.nan))
We are replacing the out-of-range values with NaN to avoid disturbance to our analysis on in-range RSSI distribution.
X_stack = X_train.stack(dropna=False)
sns.distplot(X_stack.dropna(),kde = False)
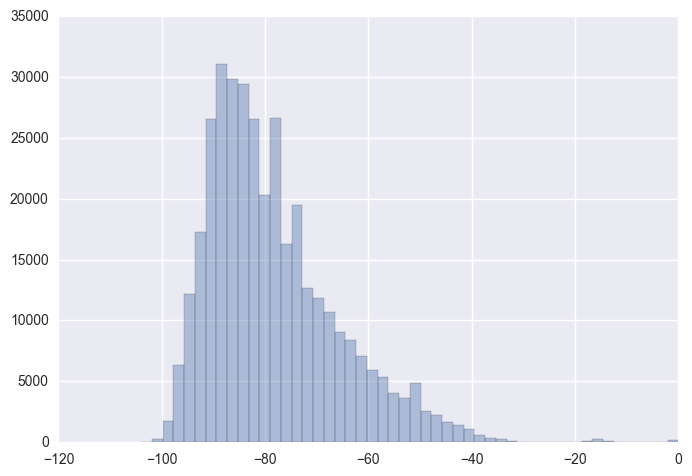
Skewness is a measure of asymmetry of distribution. Clearly, the distribution above appears right-skewed with majority of the values being on the left side of the distribution. Let’s look at the skewness value for inidividual WAP RSSI distributions! We might have to perform a log/ Box-Cox transformation to overcome the skewness.
Let’s look at percentage of out-of-range overall and column wise.
# Proportion of out of range values
sum(X_stack.isnull() == 0)/len(X_stack)
0.034605449473533938
96.1% of the values in the matrix represent Out-of-Range. This is expected as for any given measurement, only a subset of the APs might be in reach of the mobile device.
For this purpose, let’s analyze the ditribution of number of APs in range for the training data samples.
waps_in_range = (X_train
.notnull()
.sum(axis = 1))
fig, ax = plt.subplots(1,1)
sns.violinplot(waps_in_range, ax = ax)
ax.set_xlabel("Number of APs in range")
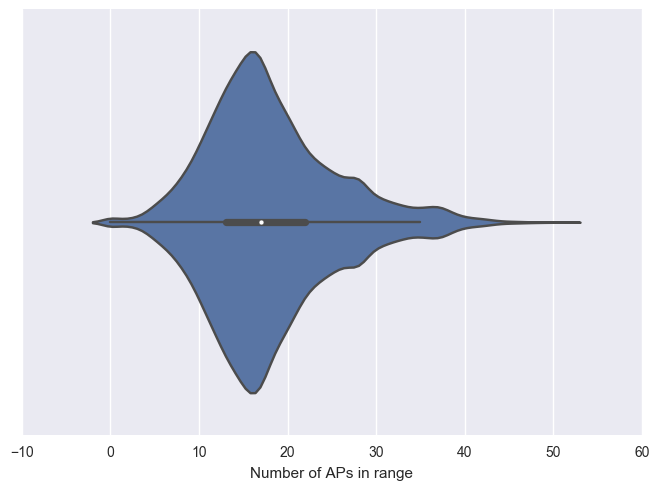
Interestingly, majority of the samples have over 13 APs in range with the maximum of 51 APs. We do observe some of the training samples with 0 APs in range. Let’s remove these samples from the training data.
print("Before sample removal:", len(X_train))
y_train = (y_train
.loc[X_train
.notnull()
.any(axis=1),:])
X_train = (X_train
.loc[X_train
.notnull()
.any(axis=1),:])
print("After sample removal:", len(X_train))
Before sample removal: 19937
After sample removal: 19861
We cannot delete training samples with just a single AP or few APs in range as that is the best information we have to localize. We can remove the RSSI columns related to APs which are not in range in any of our training samples.
# Removing columns with all NaN values
all_nan = (X_train
.isnull()
.all(axis=0) == False)
filtered_cols = (all_nan[all_nan]
.index
.values)
print("Before removing predictors with no in-range values", X_train.shape)
X_train = X_train.loc[:,filtered_cols]
X_test = X_test.loc[:,filtered_cols]
print("After removing predictors with no in-range values", X_train.shape)
Before removing predictors with no in-range values (19861, 520)
After removing predictors with no in-range values (19861, 465)
4. Skewness and Kurtosis
Skewness and kurtosis metrics are common measures to find out how close a distribution is to the normal distribution. When the data is far away from normality statistic significantly, Box-Cox transformation is one way to satisfy the normality. This is necessary for standard statistical tests, and also sometimes to satisfy the linear and/or the equal variance assumptions for a standard linear regression model
# Finding skewness ignoring out-of-range values
X_skew = X_train.skew()
sns.distplot(X_skew.dropna(),kde=False)
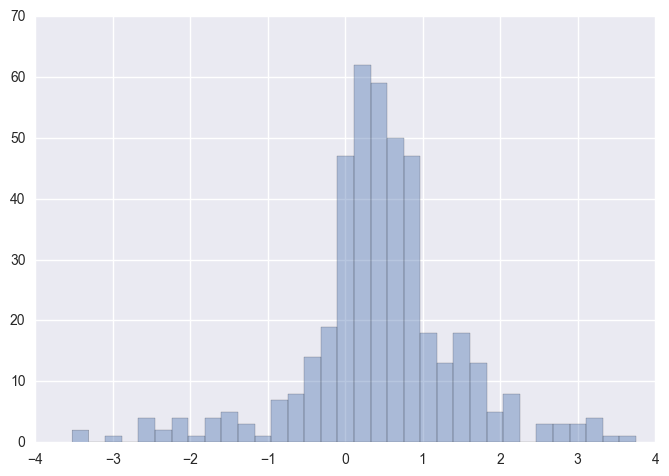
We can observe majority of the WAP columns have a low to medium positive skewness in the region (0,1). There are still a few columns outside the (1,-1) range typically considered an acceptable range of skewness.
Next, before we apply the Normality tests, we need to fill in the out-of-range values which are currently NaN. Box-Cox transformation requires all values to be positive. For this purpose, let’s transform our predictors to normal scale from the dBm scale.
Also, the out-of-range values are transformed to the absolute minimum among all in-range values. Therefore, the transformed out-of-range value represents the minimum RSSI value in the dataset.
X_exp_train = np.power(10,X_train/10,)
X_exp_test = np.power(10,X_test/10)
abs_min = (X_exp_train.apply(min).min())
X_exp_train.fillna(abs_min,inplace=True)
X_exp_test.fillna(abs_min,inplace=True)
from scipy.stats.mstats import normaltest, skewtest, kurtosistest, skew, kurtosis
def skew_score(s):
return float(skew(s).data)
def kurtosis_score(s):
return kurtosis(s)
def in_range(s):
return (s > abs_min).sum()
X_norm = pd.DataFrame({'Sample_Size': X_exp_train.apply(in_range),
'Skewness': X_exp_train.apply(skew_score),
'Kurtosis': X_exp_train.apply(kurtosis_score),
})
X_norm.head(15)
| Kurtosis | Sample_Size | Skewness | |
|---|---|---|---|
| WAP001 | 1589.911556 | 18 | 38.296999 |
| WAP002 | 1570.412878 | 19 | 38.774718 |
| WAP005 | 988.020774 | 40 | 29.692772 |
| WAP006 | 2649.644164 | 308 | 49.203758 |
| WAP007 | 2544.345308 | 578 | 48.199343 |
| WAP008 | 271.572833 | 677 | 15.905379 |
| WAP009 | 1607.562517 | 595 | 36.943490 |
| WAP010 | 1314.161272 | 87 | 33.682378 |
| WAP011 | 8749.417194 | 2956 | 91.377383 |
| WAP012 | 2186.418420 | 2983 | 46.709112 |
| WAP013 | 2224.512227 | 1975 | 41.630716 |
| WAP014 | 2208.568286 | 1955 | 41.864942 |
| WAP015 | 254.567147 | 1007 | 14.216486 |
| WAP016 | 501.190217 | 999 | 20.185881 |
| WAP017 | 662.356727 | 84 | 24.103059 |
Let’s explore the relationship between Kurtosis scores and Skew scores.
sns.jointplot(y="Kurtosis", x="Skewness", stat_func= None, data=X_norm)
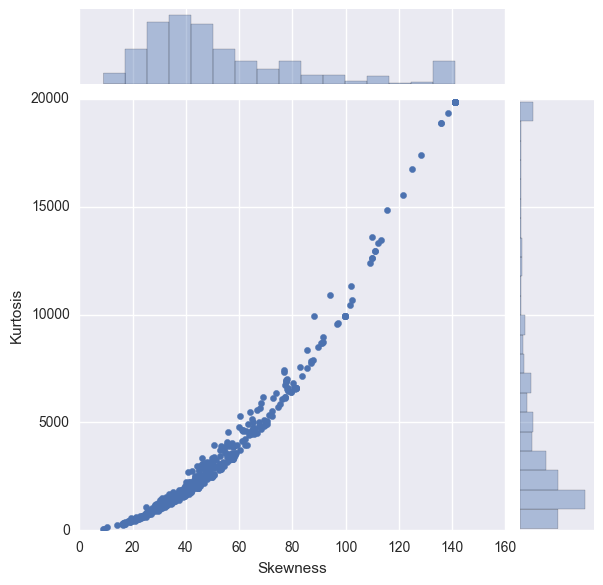
Skewness: For normally distributed data, the skewness should be about 0. A skewness value > 0 means that there is more weight in the left tail of the distribution. Similarly, a negative value indicates a left-skewed distribution with more weight on the right tail.
Clearly, many of the predictors have a skewness outside the expected range of 0,0
Kurtosis: Kurtosis is the fourth central moment divided by the square of the variance. If a distribution has positive kurtosis, that means it has more in the tails than the normal distribution. Similarly, if a distribution has a negative kurtosis, it has less in the tails than the normal distribution.
In the above figure, for the columns with a higher skewness score, the kurtosis is also more extreme. The figure shows significant number of predictors with extremely high skewness and kurtosis.
5. Box-Cox Transformation
To apply the Box-Cox transform we have to first make all our data positive. As we performed the exponential transformation, our data is already positive.
def box_cox_lambda(s):
_, maxlog = stats.boxcox(s)
return maxlog
lambda_bc = X_exp_train.apply(box_cox_lambda)
X_boxcox_train = X_exp_train
X_boxcox_test = X_exp_test
for wap in X_boxcox_train:
# Training data transform
X_boxcox_train.loc[:,wap] = stats.boxcox(X_exp_train.loc[:,wap],lmbda = lambda_bc.loc[wap])
# Test data transform
X_boxcox_test.loc[:,wap] = stats.boxcox(X_exp_test.loc[:,wap],lmbda = lambda_bc.loc[wap])
sns.distplot(lambda_bc, kde = False)
plt.title("Distribution of Box-Cox $\lambda$ across predictors")
plt.tight_layout()
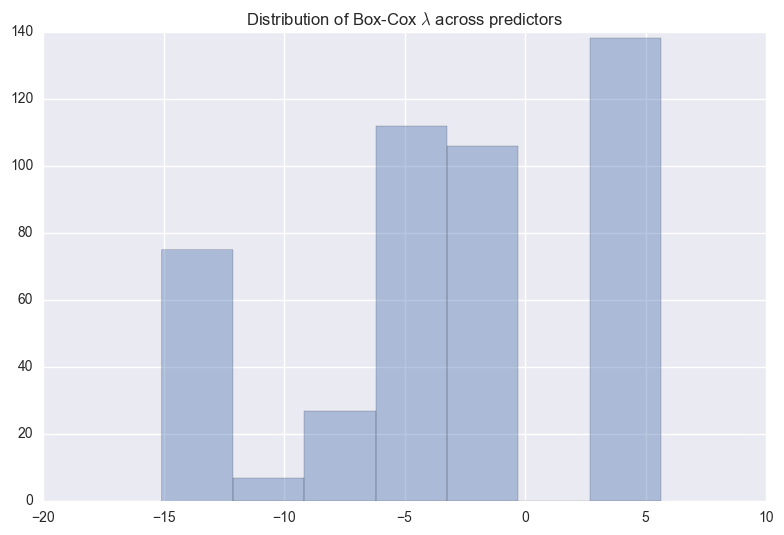
The above figure shows the distribution of $\lambda$s that maximize log-likelihood function for each predictor. We can observe the two biggest bars are located at +5 and -2.5.
# After Box-Cox
X_norm_post_boxcox = pd.DataFrame({'Skewness': X_boxcox_train.apply(skew_score),
'Kurtosis': X_boxcox_train.apply(kurtosis_score),
'BoxCox_Lambda': lambda_bc})
X_norm_post_boxcox.head(10)
| BoxCox_Lambda | Kurtosis | Skewness | |
|---|---|---|---|
| WAP001 | 5.636369 | -3 | 0.000000 |
| WAP002 | 5.636369 | -3 | 0.000000 |
| WAP005 | 5.636369 | -3 | 0.000000 |
| WAP006 | -15.078885 | -- | 0.000000 |
| WAP007 | -6.989974 | 29.3916 | 5.602818 |
| WAP008 | -6.063101 | 24.3721 | 5.135374 |
| WAP009 | -5.750808 | 28.4107 | 5.514591 |
| WAP010 | 5.636369 | -3 | 0.000000 |
| WAP011 | -0.975030 | 1.93886 | 1.982143 |
| WAP012 | -0.968725 | 1.87163 | 1.965486 |
The kurtosis and skewness seems to have greatly reduced compared to before the Box-Cox transformation. Let’s compare!
fig, (ax1,ax2) = plt.subplots(1,2)
ax1.scatter(y="Kurtosis", x="Skewness", data=X_norm)
ax1.set_xlabel("Skewness")
ax1.set_ylabel("Kurtosis")
ax1.set_title("Pre- Box-Cox")
ax2.scatter(y="Kurtosis", x="Skewness", data=X_norm_post_boxcox)
ax2.set_xlabel("Skewness")
ax2.set_ylabel("Kurtosis")
ax2.set_title("Post- Box-Cox")
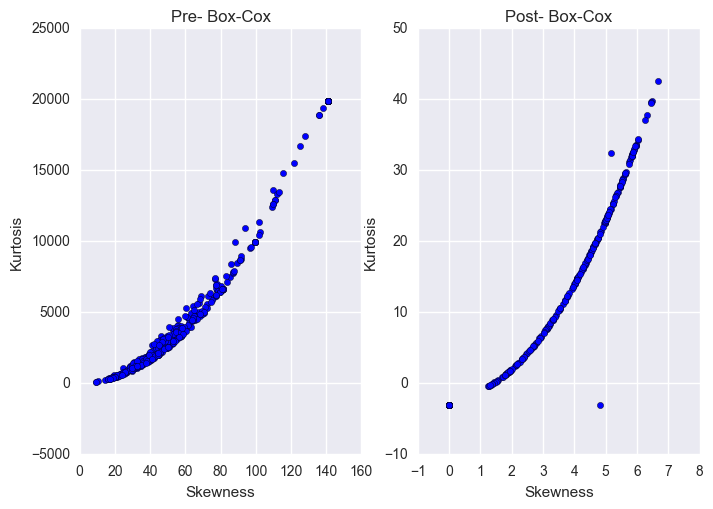
Note that the scales for the two figures above are two orders of magnitude lower for Kurtosis and one order of magnitude lower for Skewness after the Box-Cox transformation.
I am interested in observing the univariate distribution of skewness and kurtosis to find out if majority of our predictors are now close to normal or not.
sns.jointplot(y="Kurtosis", x="Skewness", stat_func = None,data=X_norm_post_boxcox)
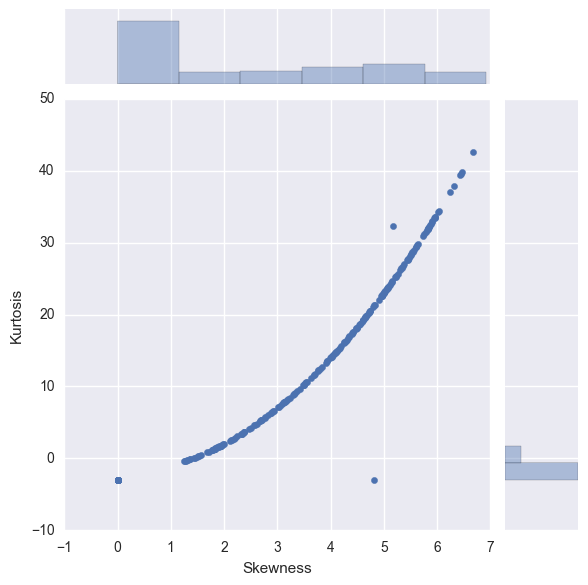
We can observe the biggest bars are located in the region [0,1) for skewness and [0,-3) for kurtosis.
Next, we can explore how much of the variance in the dataset is explained by the predictors using Principal Component Analysis (PCA).
6. Dimensionality Reduction
Dimensionality reduction is one of the key techniques to reduce the complexity.
PCA is a simple dimensionality reduction technique that applies linear transformations on the original space. Among all the orthogonal linear projections, PCA minimizes the reconstruction error, which is the distance between the instance and its reconstruction from the lower-dimensional space. That is sum of the distances between points in original space and the corresponding points in lower-dimensional space.
Before we can perform the PCA analysis, we need to bring the predictors to the same scale. Then, we analyze the correlations between the predictors and remove highly correlated predictors. This is because adjoining nearly correlated variables increases the contribution of their common underlying factor to the PCA. We can remove highly correlated predictors algorithmically or removing the correlations by whitening the data (conversion to Identity Covariance Matrix).
6.1 Feature Scaling
Most models require the predictors to be on the same scale for better performancee. The main exceptions are decision-tree based models which are not dependent on scaling as the splits are univariate.
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_std_train = sc.fit_transform(X_boxcox_train)
X_std_test = sc.transform(X_boxcox_test)
X_std_train = pd.DataFrame(X_std_train)
X_std_test = pd.DataFrame(X_std_test)
After the Box-Cox transformation and scaling, few of the predictors are reduced to a constant value of 0. Let’s remove these predictors from the training and test data
all_zero= ((X_std_train == 0)
.all()==False)
filtered_cols = (all_zero[all_zero]
.index
.values)
print("Before removing predictors with only zeros", X_std_train.shape)
X_rm_train = X_std_train.loc[:,filtered_cols]
X_rm_test = X_std_test.loc[:,filtered_cols]
print("After removing predictors with only zeros", X_rm_train.shape)
Before removing predictors with only zeros (19861, 465)
After removing predictors with only zeros (19861, 254)
6.2 Predictor Correlations
Read this explanation about how PCA tends to over-emphasize the contributions of correlated predictors.
X_train_corr = X_rm_train.corr()
fig = plt.figure(figsize=(15,15))
sns.heatmap(X_train_corr,xticklabels=False, yticklabels=False)
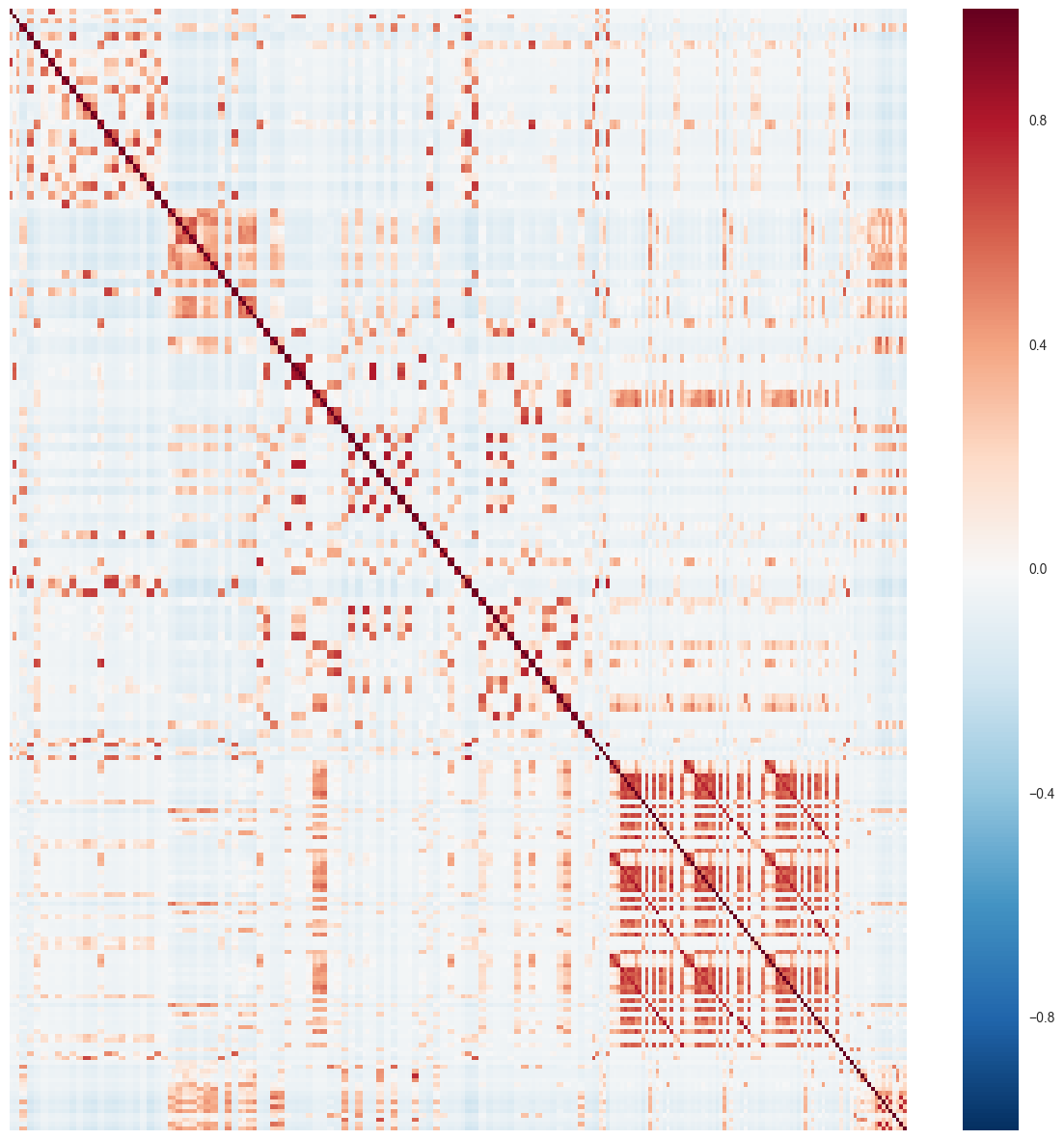
Clearly, we observe clusters of predictors that are highly correlated. Let’s assign a threshold of 0.9 and see how many predictor pairs have correlation above this threshold.
corr_stack = X_train_corr.stack()
corr_thresh = 0.9
# Total entries in correlation matrix above threshold
Nthresh = (abs(corr_stack) >= corr_thresh).sum()
# Subtracting the correlation of predictor with themselves which is equal to 1
Nthresh -= 254
# Pairwise correlations appear twice in the matrix
Nthresh *= 0.5
Nthresh
16.0
Only 16 predictor pairs have correlation above our defined threshold. As they are a small number compared to the total number of predictors, I do not remove any at this stage. In general, we can remove half of these predictors in the following manner:
Determine the two predictors A and B with largest absolute pairwise correlation.
Determine average correlation between A and other predictors. Repeat this for B.
If A has a larger average correlation, remove it. Otherwise, remove B.
Repeat 1-3 until no absolute correlation is above threshold.
The above technique was highlighted in the Chapter 3 of Applied Predictive Modeling book. I’ve written a few personal notes on the most important information I learnt reading this chapter. You can find it here.
6.3 Principal Component Analysis (PCA)
Dimensionality reduction is one of the key techniques to reduce the complexity.
PCA is a simple dimensionality reduction technique that applies linear transformations on the original space. Among all the orthogonal linear projections, PCA minimizes the reconstruction error, which is the distance between the instance and its reconstruction from the lower-dimensional space. That is sum of the distances between points in original space and the corresponding points in lower-dimensional space.
An important point to remember about PCA is that it is an unsupervised form of dimensionality reduction. This means the response variables are not taken into consideration at any point of the transformation. sci-kit learn provides convenient methods to perform PCA which I’ll be using directly.
from sklearn.decomposition import PCA
pca = PCA()
pca.fit(X_rm_train)
PCA(copy=True, iterated_power='auto', n_components=None, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
# Borrowed from Sebastian Raschka's Python Machine Learning Book - Chapter 5
fig, ax = plt.subplots(1,1)
ax.bar(range(1, 255), pca.explained_variance_ratio_, alpha=0.5, align='center')
ax.step(range(1, 255), np.cumsum(pca.explained_variance_ratio_), where='mid')
ax.set_ylabel('Explained variance ratio')
ax.set_xlabel('Principal components')
ax.set_yticks(np.arange(0,1.1,0.1))
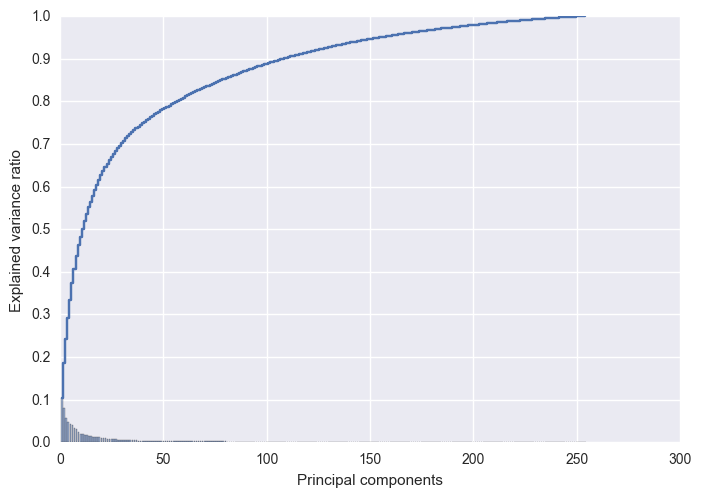
Roughly 95% of the variance is explained by the first 150 eigen vectors. Before, we perform the dimensionality reduction on our data, let’s analyze the reconstruction error as a function of the dimensions.
X_rm_train = np.array(X_rm_train)
mu = np.mean(X_rm_train,axis = 0)
recon_error = []
for nComp in range(1,X_rm_train.shape[1]):
#pca.components_ is already sorted by explained variance
Xrecon = np.dot(pca.transform(X_rm_train)[:,:nComp], pca.components_[:nComp,:])
Xrecon += mu
recon_error.append(sum(np.ravel(np.abs(Xrecon- X_rm_train)**2)))
pd.Series(recon_error).plot()
plt.xlabel("Number of Eigen Vectors")
plt.ylabel("Reconstruction Error")
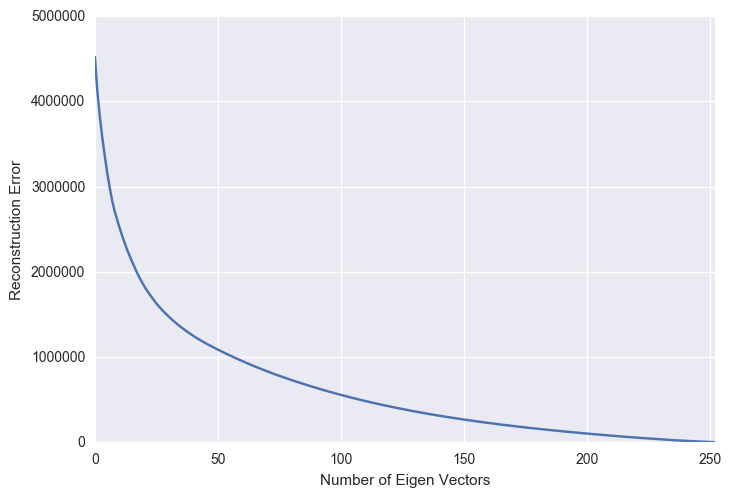
As the number of principal components used for the reconstruction increases, the reconstruction error expectedly decreases. This figure is a mirror image of the previous explained variance ratio figure.
As 95% of the explained variance is explained by top 150 components, I will reduce my training and test data to 150 dimensions.
Ndim_reduce = 150
X_train_pca = pca.transform(X_rm_train)[:,:Ndim_reduce]
X_test_pca = pca.transform(X_rm_test)[:,:Ndim_reduce]
X_train_pca.shape,X_test_pca.shape
((19861, 150), (1111, 150))
7. Conclusion
In this blog, we started from the raw UJIIndoorLoc dataset and worked our way into understanding the characteristics of predictor data. Accordingly, we applied Box-Cox transformation to bring the predictors closer to the normal distribution and reduce the skewness. Due to the complexity of dealing with close to 500 predictors, we conducted a principal component analysis and found out that over 95% of the latent information is contained within the top 150 principal components. In the next blog, we take a side-turn and focus on the response features and their relationship with the predictors. This will lead to the formulation of our cost function. Thanks for reading!